











 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


ECCV2020论文《Dive Deeper Into Box for Object Detection》解读
更新时间:2020年09月14日14时59分 来源:传智播客 浏览次数:
1 前言
该文章作者团队来自香港中文大学、腾讯优图、思谋科技等,收录于ECCV2020.现阶段,无锚框的目标检测方法称为流行,该论文提出了深度分析box来提升检测性能的方法。
在目标检测领域,虽然无锚框的取得成功,但仍存在一些问题。比如,检测框框的中心点并不是目标的中心点,如下图所示:

而且中心点会出现漂移。

为了解决这些问题,文章提出了一种边框重组的方法,通过对中心点box的回归过程,考虑语义一致性得到检测结果。
2 网络架构
在该论文中,基于FCOS构建了DDBNet,如下图所示:
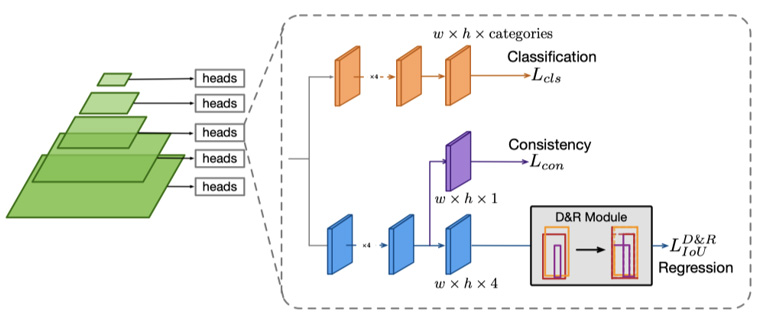
D&R模块通过将预测的框划分为边界进行训练来重组预测框,该边界在回归分支后面进行连接。在训练阶段,一旦边界框预测在每个像素处回归,D&R模块会将每个边界框分解为四个方向边界。然后,根据它们与ground truth的实际边界偏差对同类边界进行排序。因此,通过重新组合排位边界,可以期望得到更准确的box框预测,然后利用IoU loss对其进行优化。
D&R模块由四个步骤组成,如下图所示:
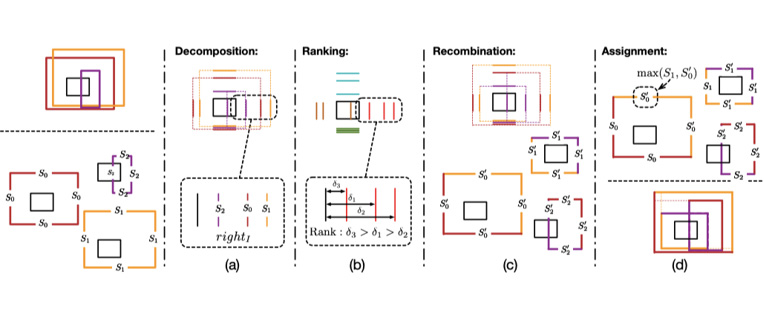
2.1 分解
将一个预测的box划分为四个边界的置信度。然后将四种边界分为四组,分别是:
left = {l0,l1,...,ln},right = {r0,r1,...,rn},bottom = {b0,b1,..., bn},top = {t0,t1,...,tn}。
2.2 排序
考虑到IoU损失的约束,有利于具有较小并集和较大交集区域的预测框,最佳框预测的IoU损失预计最低。因此,在第二步中可以直接遍历所有边界后进行重新排列以获得最优的框,然而,以这种方式,计算复杂度非常高。为了避免这种暴力方法带来的繁重计算,本文采用了一种简单有效的排序策略。对于目标实例的每个边界集,计算到目标边界集合的偏差。然后,将每个集合中的边界按相应的偏差排序,因此,靠近ground truth的边界比远处的边界具有更高的等级。作者发现这种排序策略效果很好,并且排序噪声不会影响网络训练的稳定性
2.3 重组
将具有相同等级的四个集合的边界重新组合为新框。然后,将分解后的边界集合和目标边界集合之间的IoU看作为四个边界的重组置信度。重组边界的置信度表示为形状为N×4的矩阵。
2.4 分配得分
现在得到了原始边界和重组后的边界两组边界得分。每个边界的最终置信度是使用两组边界得分中的较高得分来分配的,而不是完全使用其中一组。如果重新组合后的低位框包含的边界离ground truth很远,这会导致重组后四个边界的置信度远低于其原始边界,这些严重漂移的置信度分数会导致训练阶段的梯度反向传播不稳定,因此选择得分较高的一组
3 模型训练
网络整体的损失函数是:
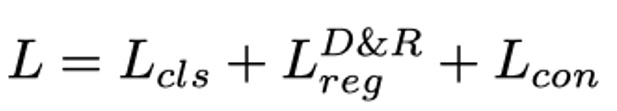
其中分类损失使用的是Focal Loss,另外两部分分别是边框回归损失和语义一致性损失
3.1 边框回归损失
为了进行可靠的网络训练,在基于ground truth和最优box以及相应的更好边界得分估算的IoU损失的监督下来优化每个边界。边框回归损失包括两个部分:
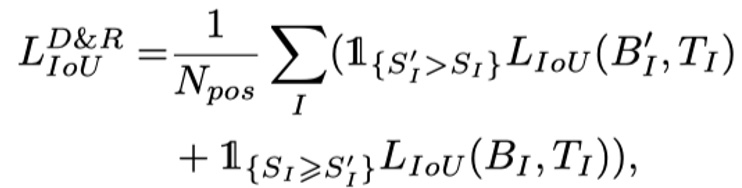
分别是重组框和原始框与标签之间的交并比IOU分数,选择每个边界的梯度以更新网络。
3.2 语义一致性损失
在根据语义一致性自主确定像素的标签后,网络在学习过程中考虑了每个正向像素的内在重要性,类似于FCOS中的中心度得分。因此,DDBNet网络能够强调一个实例中更重要的部分,学习起来更加有效。具体地,将每个像素的内在重要性定义为预测框与ground truth之间的IoU。然后,在内在重要性的监督下,将估计每个像素语义一致性的额外分支添加到网络中。语义一致性的损失表示为:
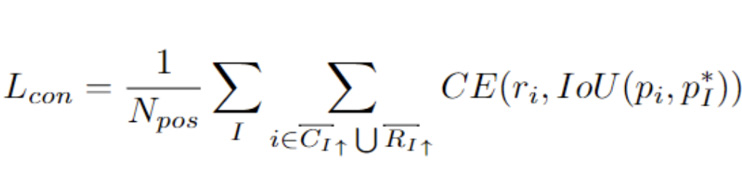
4 实验
该论文作者在COCO数据集上进行了实验。
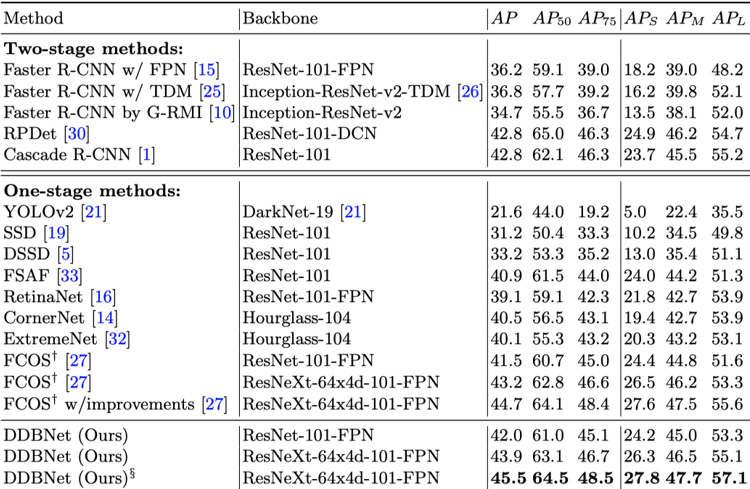
4.1 对比实验
与RCNN系列、yolo系列、ssd等都做了对比实验,本文的结构优于其他模型。
4.2 消融实验
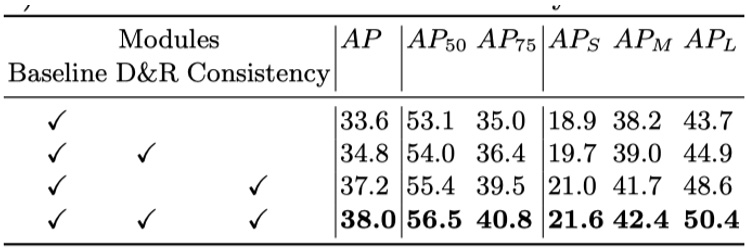
作者将D&R 模块和语义一致性进行了实验,结果表明加入后效果较好。
4.3 检测效果
红色框表示真实值。绿色框表示预测结果,有较高的IOU。黑色框也是预测结果,但IOU值较小。

猜你喜欢:
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
